We're a bit late to the party, but finally just upgraded our Orion environment to the newest versions (we'd missed a few. We went from NPM 12.0/SAM 6.3/VMAN 7.2 to 12.2/6.6/8.2). We are taking advantage of the new Orion VMAN Polling and used the Migration Wizard under Virtualization Settings to move from the VMAN Appliance to Orion VMAN.
Prior to our upgrade, we were getting accurate DataStore latency metrics, but immediately after the upgrade the latency metrics being reported for datastores in Orion do not match up with the DataStore latency metrics being showed in vCenter (and yes, we poll all of our virtual environments through the vCenter. No standalone hosts here.). Below is the example of one that brought our attention to this issue since all of a sudden we started alerting on this datastore for having high latency. However, we had our Virtualization adminstrator guy check it out and he said that he is seeing a much lower number in vCenter. After discovering this we looked up a bunch of other datastores and saw that they are also reporting completely different metrics for latency after the upgrade and none of them match up with any metrics we can find in vCenter.
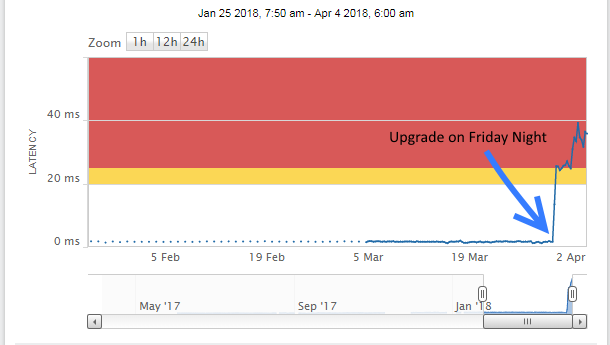
Prior to Friday night's upgrade, this datastore consistently reported around 1ms average latency. After the upgrade it now reports latency ranging from 30 to 40 ms... vCenter still consistently reports around 1ms latency. There are at least 8 or 10 other datastores we've identified that are like this and we have no clue where these latency numbers are coming from. It's getting it from somewhere, but we can't find it...
To elaborate on our environment, we are monitoring through our vCenters. We don't poll any ESX hosts individually. Our vCenters are all running VMware version 6.0 and we had no problems monitoring this stuff with the old VMAN Appliance. Also, we did try removing all of our virtualization devices and adding them back in with the thinking that maybe something weird happened during the VMAN appliance to Orion migration. However we are still seeing the same issue, so that wasn't it.





