Auf Reddit unter r/sysadmin habe ich diese Tage einen Beitrag entdeckt, in dem jemand frei übersetzt das folgende beklagt:
„Als genereller System Administrator muss man über eine Menge Dinge bescheid wissen. Unter anderem Windows, Linux, Mac, AD, Virtualisierung, Routing und Switching, Exchange, Vulnerability Management, Antivirus, Scripts, Datenbanken, und Hardware jeglicher Art. […] Obwohl man Generalist/Universalist ist, wird Expertenwissen erwartet.“
Hand aufs Herz, wer erkennt sich da wieder?
Gerade in KMUs ist es leider normal, dass ein zu kleines IT Team zu viele Aufgaben übernehmen muss, und um irgendwie über die Runden zu kommen, ist ein breit gestaffeltes Wissen sinnvoller als bei Randthemen in die Tiefe zu tauchen.
Im Bedarfsfalle kann man sich immer noch externes Wissen dazu holen, wie z.B. Herstellersupport, oder outsourced-DBA.
Ich möchte keine Diskussion darüber starten, ob diese Art und Weise die beste ist, aber wenn man dem folgt gibt es zwei Probleme – mindestens.
Zum einen stellt man sich selbst die Frage „Kann ich das noch, oder brauche ich dafür jemand anders?“ und zum anderen bekommt man die Frage gestellt „Warum konntest du das nicht selbst?“
Und selbst wenn man es selbst gelöst hat, sieht man sich vielleicht noch mit „Warum hat das so lange gedauert?“ konfrontiert.
Halt! Stopp! Keine Panik! Hier kommen wir ins Spiel.
Werkzeuge für SysAdmins
Troubleshooting kann nicht beginnen, bevor das Problem grob lokalisiert wurde. Wenn man auf die eingangs erwähnten Schichten schaut, kann das allein schon einen signifikanten Zeitaufwand darstellen.
Wie wäre es mit so etwas:
Für mich und manche Leser ist das ein vertrautes Werkzeug, andere sehen das sicher zum ersten Mal. Es gehört zu unserer Orion Plattform und heißt AppStack.
Plattform und heißt AppStack.
Man sieht automatisch die Abhängigkeit zweier Anwendungen, das Betriebssystem, die Virtualisierungsschicht bis hinunter in den Bereich Storage, immer aktuell.
Ein simples mouse-over zeigt mir den Status der beteiligten Elemente an und in meinem Fall bringt mich die zweite rote Kugel schon ziemlich nahe zum Ziel:
Natürlich ist es nicht immer so einfach, aber ihr könnt euch vorstellen, wie viel Arbeit einem ein solches Werkzeug abnehmen kann, und wenn man quasi mit der Nase in die Richtung des eigentlichen Problems geschubst wird, hat man in vielen Fällen schon gewonnen.
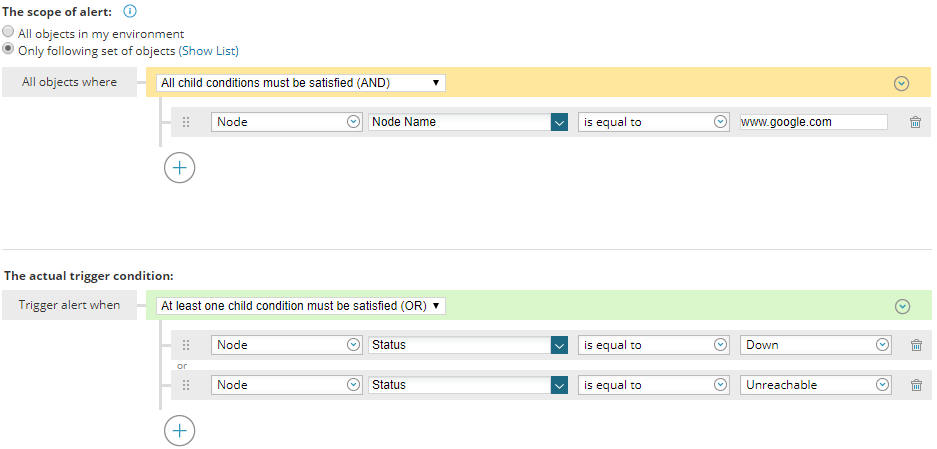
Bei der Ansicht des Fensters sehe ich aber noch etwas anderes und möchte es mir im Detail ansehen. Die DB berichtet „irgendwas ist rot“:
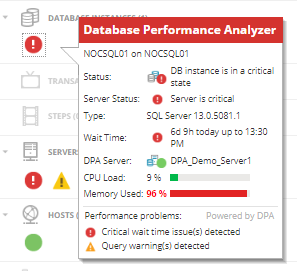
Aber was genau bedeutet das? Hier bekommen wir mehr Informationen:
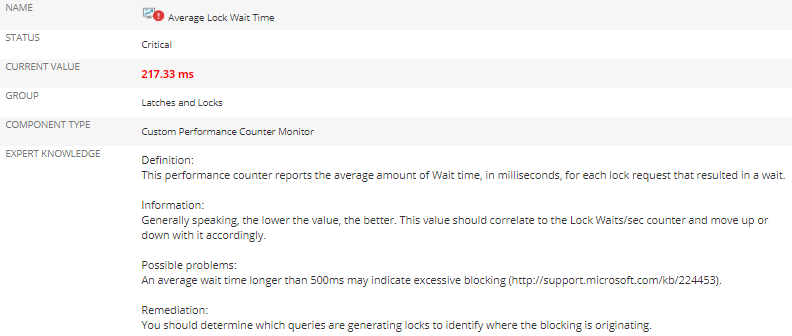
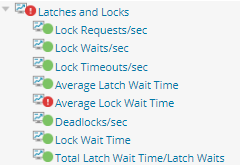
Ich kann mit meinen Werkzeugen noch tiefer gehen und tatsächlich das Query sehen, dass hier blockiert, auch von wo und von wem es ausgeführt wurde, sowie einige unterstützende Informationen.
Ich weiss aber jetzt schon, dass ich als Generalist entweder den Hersteller der jeweiligen Anwendung oder aber zumindest einen Entwickler brauchen werde.
Definitiv ein Fall der Kategorie Spezialwissen, aber ich kann es dokumentieren, und die mir durch Database Performance Analzyer (DPA) zur Verfügung stehenden Informationen helfen dem Experten, das Problem schnell zu beseitigen.
Ein weiteres Feature der Orion Plattform, in diesem Fall geliefert durch Server & Application Monitor (SAM), ist das automatische Erkennen der Abhängigkeiten von Anwendungen und auch hier hilft ein Blick, um Zusammenhänge zu erkennen.
Auf einem meiner Webserver, dem Namen nach in der Cloud, können meine Benutzer nicht zuverlässig oder nur langsam Einloggen, um mit der Webanwendung zu arbeiten.
Wie man sieht, liegt die Ursache nicht am Webserver, sondern an der Verbindung zum Domain-Controller.
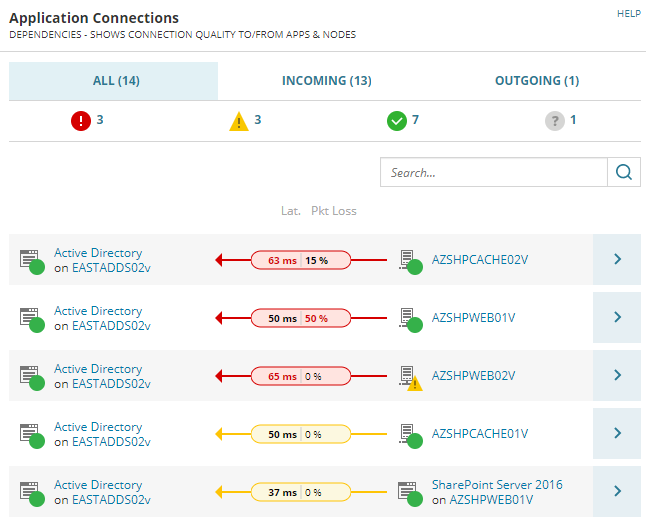
Ein Mausklick auf die Verbindung zeigt mir Details:
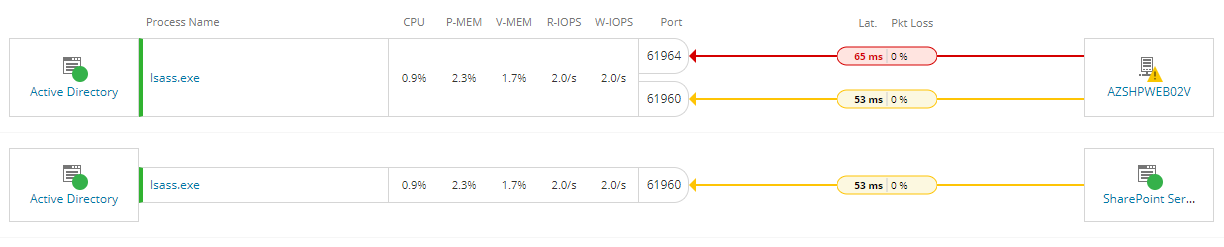
Ich muss kein Netzwerk-Spezialist sein, um sowohl den Webserver als auch den DC aus der Fehlerkette ausschließen zu können.
Für diejenigen die wissen möchten, wie dieses Feature funktioniert:
Der Orion Agent sitzt auf den Kisten und überprüft, welche internen Prozesse an welchen Ports lauschen, und von wo Daten herkommen bzw. hingehen.
Wenn die andere Maschine ebenfalls überwacht wird, geschieht dort das gleiche und Orion zeigt die Verbindung der Maschinen sowie der Anwendungen an.
Da beide Elemente wahrscheinlich kritisch für das Unternehmen sind, empfiehlt es sich die Verbindung als NetPath anzulegen, leider gibt meine Laborumgebung dieses Beispiel nicht her, also muss ich improvisieren.
anzulegen, leider gibt meine Laborumgebung dieses Beispiel nicht her, also muss ich improvisieren.
Wer mit NetPath noch nicht vertraut ist: NetPath visualisiert die Verbindung von Anwendungen über verschiedene Standorte bis in die Cloud.
Um das Konzept zu verstehen, denkt kurz an Traceroute – aber dann stoppt. Traceroute nutzt entweder ICMP oder UDP was zwar nett, aber irrelevant für die meisten Anwendungen ist, die selbstverständlich über TCP kommunizieren.
Daher bietet NetPath eine TCP basierende „hop-by-hop“ Analyse.
Ich öffne einen hybriden Pfad, der meinem obigen Beispiel recht nahekommt:
Der Pfad selbst sieht so aus:
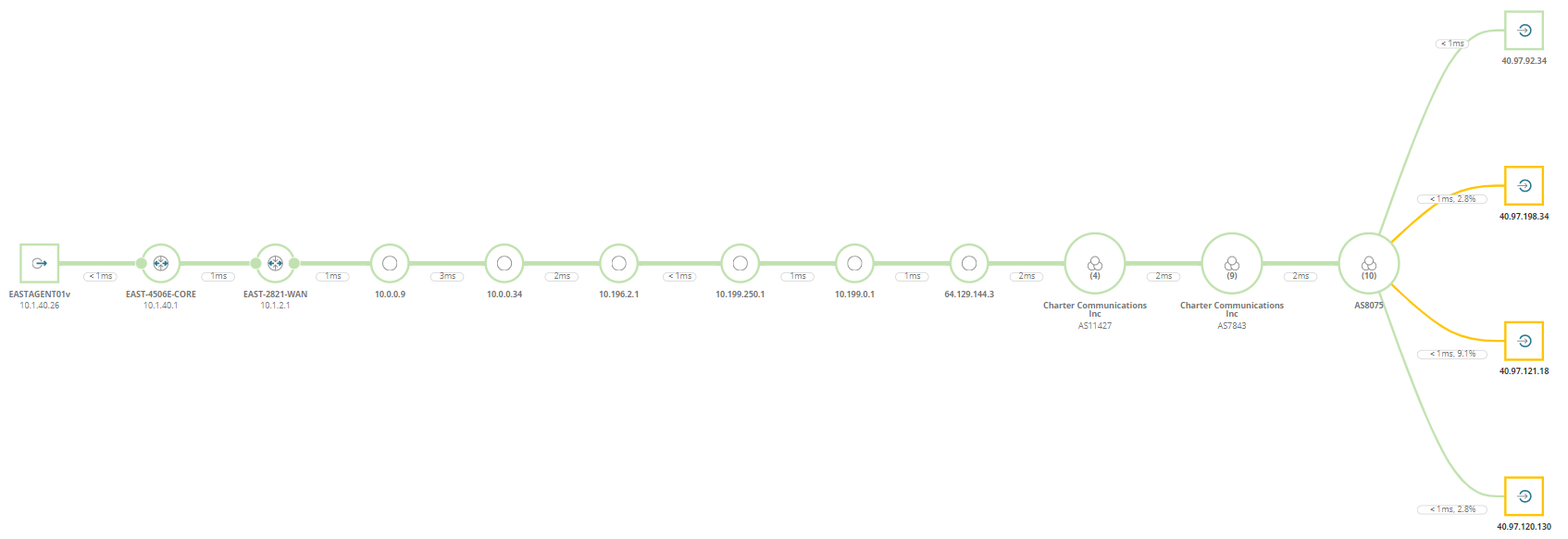
Im Produktivbetrieb ist der Pfad lebendig – man kann auf alles Klicken für weitere Informationen, eine Zeitachse benutzen, um Änderungen zu sehen, aber das Problem ist hier schon offensichtlich.
Links ist mein Netz, alles ist Grün, irgendwo in der Mitte lande ich bei meinem ISP und auch dort ist alles okay.
Rechts jedoch, beim Cloud-Anbieter, gibt es Paketverlust zu drei von vier Zielcontainern, die sich dort in der Rotation befinden.
Dies ist ein weiterer Fall von „jetzt muss der Hersteller ran“ und wir helfen sogar Kontaktdaten nach einem weiteren Mausklick:
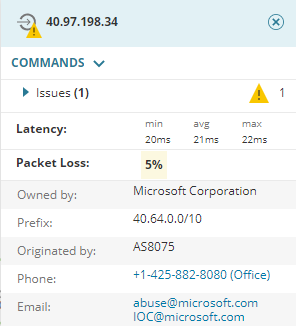
Ein weitertes Beispiel gebe ich euch noch mit auf den Weg. Wieder muss ich etwas improvisieren.
Nehmen wir an, AppStack zeigt uns Probleme mit einem IIS an.
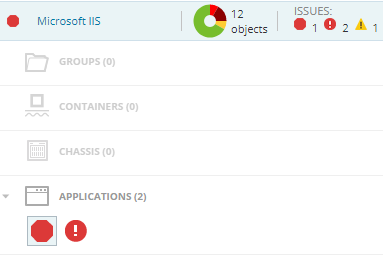
Und der darunterliegende Server ist nicht glücklich:
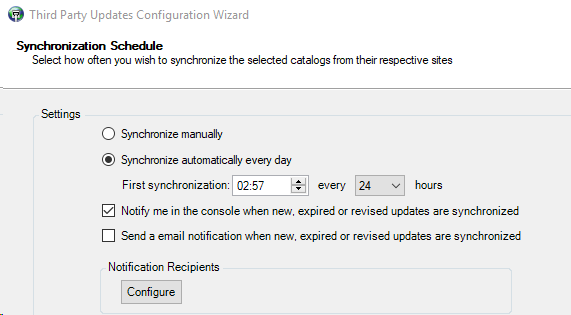
Schaut nach rechts oben und klickt auf „Perfstack“:
PerfStack ist ein Werkzeug, um beliebige Daten in Relation zu setzen. Man sieht gerade nur die CPU, die von der vorherigen Seite übernommen wurde.
Auf der rechten Seite ist ein Doppelwinkel:
Ein Klick öffnet den Knoten:
Und ein Klick darauf zeigt die Informationen an, die wir von dem Server sammeln:
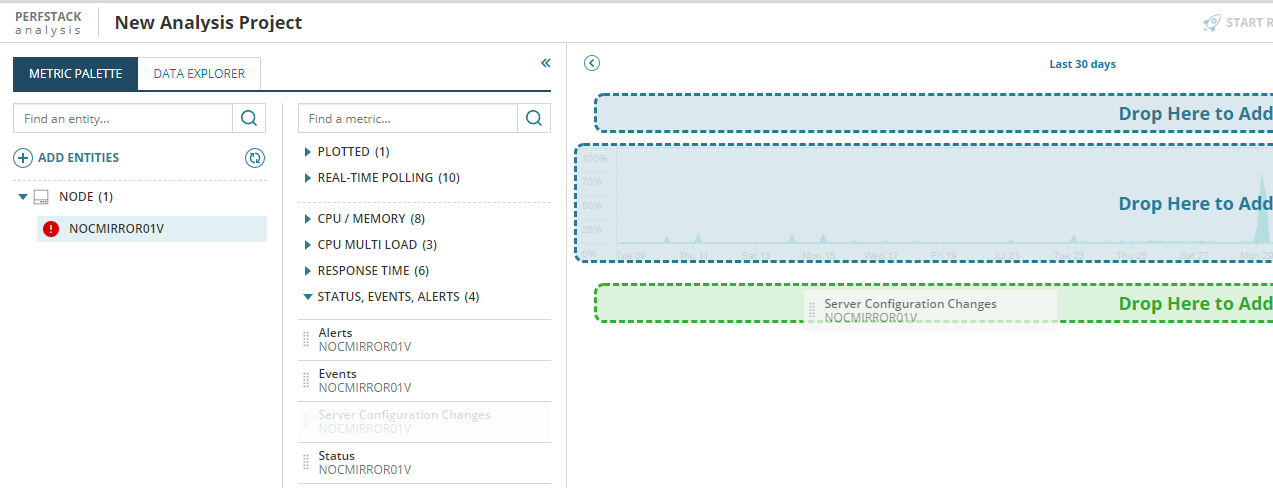
Mittels Dragp&Drop kann man nun weitere Informationsschichten in die Grafiken ziehen.
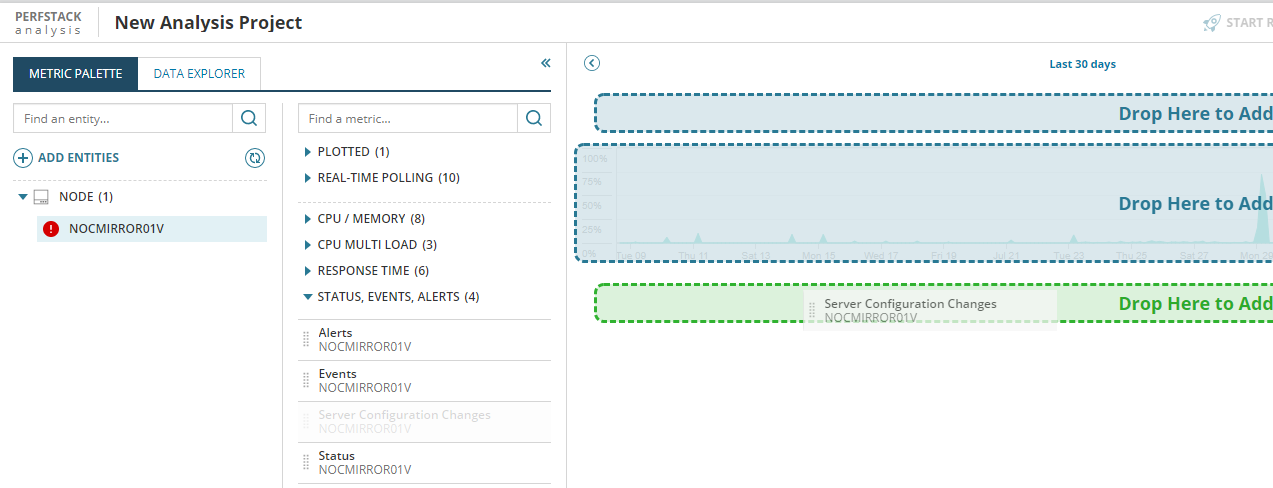
Das Hinzufügen von Events und Konfigurationsänderungen zeigt mir auf der Zeitachse einen Zusammenhang mit dem Anstieg in der CPU Auslastung an:

Ich klicke auf die Spalte mit der Konfiguration:
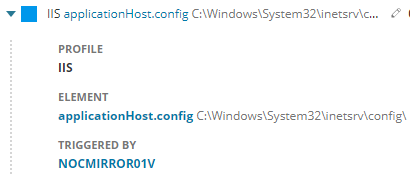
Interessant. Ich brauche mehr Details:
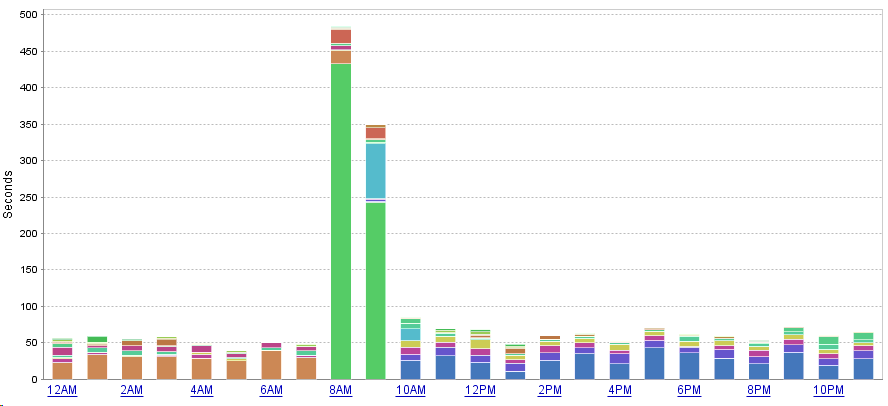
Auch als nicht-IIS-Admin sehe ich, dass eine weitere Webseite hinzugefügt worden ist.
Tatsächlich sehe ich rechts oben sogar von wem.
Ich glaube, ich rufe Rose an, um den Sinn eines Change-Protokolls zu diskutieren.

Bis dahin, macht’s gut, und stresst euch nicht zu viel.


