Keeping today's complex applications healthy and performant is no small task, especially when we find ourselves spending more time putting out fires rather than preventing them. Ben Franklin knew what he was talking about when it comes to keeping yourself healthy. Companies and healthcare providers spend millions of dollars on preventive care because they know the cost of troubleshooting and fixing an individual's health is exponentially more expensive.
I can't think of another analogy that fits better than this one when discussing today's complex IT environments and our lack of effective life cycle monitoring. We know how important it is to plan, but it seems always to take a back seat to day-to-day operations. To get an ounce of prevention, you need to have control; you gain control by getting visibility into your entire IT environment and quickly and accurately diagnosing problems. It starts by leveraging the information you collect to benchmark your current state. Knowing your status today—good or bad—is essential to prepare for change, optimize your resources, and maximize your IT investments. It’s difficult not to get caught up with the seemingly unending and resource-intensive tasks associated with keeping our systems up and running. We seem to spend most of our time firefighting, leaving little time to step back, evaluate our environment, and take preventive measures.
IT environments have become more complex, driven by newer and emerging technologies. The business demands more applications, more capabilities across data centers and multiple cloud providers in less time. Unless you have a proper plan to deal with change and dedicate time to regularly optimizing your environment, you won’t be able to deliver on your commitment to your customers. In summary, you have no choice but to start thinking about how much planning and optimization needs to be part of your life cycle monitoring strategy. Today's IT environments force companies to take planning and optimization seriously and give it the time it deserves.
What Is Life Cycle Monitoring?
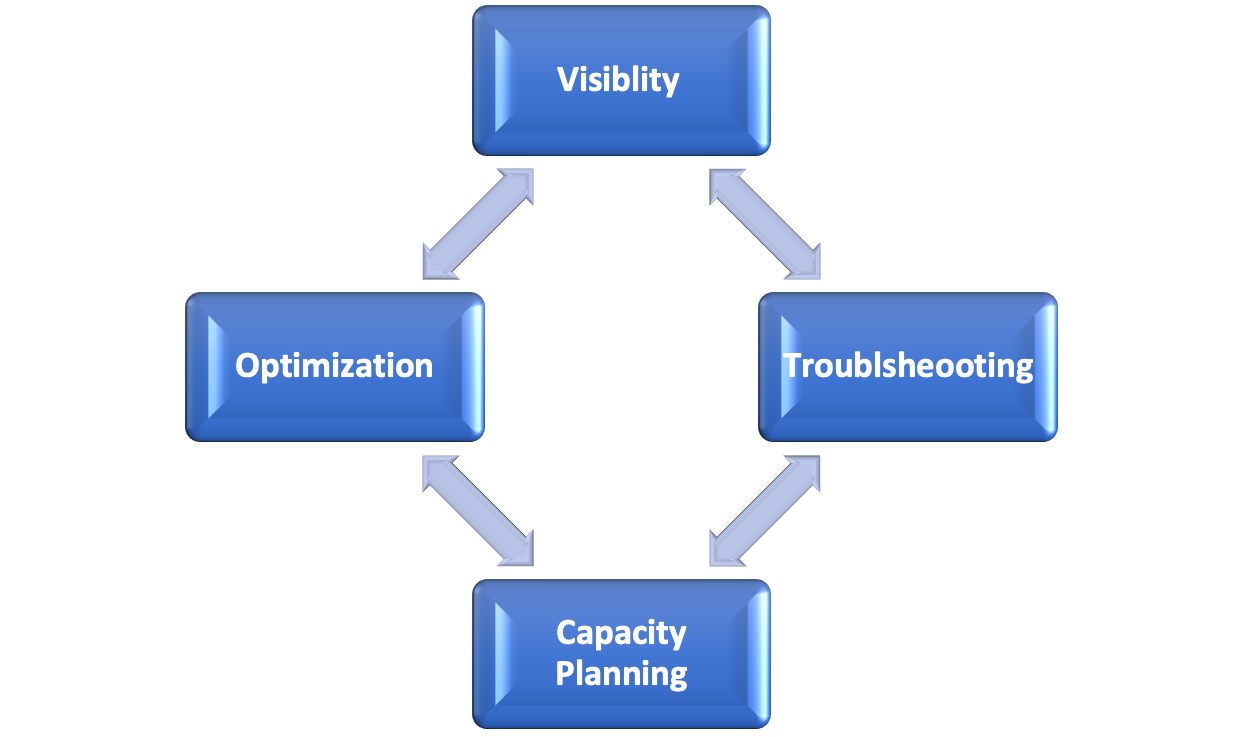
Life cycle monitoring doesn't have an end to it; it’s a continuous process. This is not a "set it and forget" strategy—that would be disastrous. At a high level, life cycle monitoring includes four elements:
1. Visibility
2. Troubleshooting
3. Capacity planning
4. Optimization.
Although I define it as a cycle, it isn't that simple. All four elements of life cycle monitoring feed off each other. There also isn't one that’s more important than the other, but you won't be successful if any are absent from your life cycle monitoring strategy. You are constantly getting new insights that improve your visibility. Troubleshooting doesn’t necessarily follow visibility, but without visibility, your troubleshooting might be likened to finding the needle in the proverbial haystack. Planning and optimization feed off visibility and lessons learned from problems you solve. Collectively, life cycle monitoring provides you the insights you need to make good decisions, make them quickly, and maximize your IT investment amid constant change.
Digging Deeper Into Life Cycle Monitoring
To continue our analogy, before someone can put together a health prevention plan, they need to have a baseline of their health. This is no different in the IT world. To get a baseline of life cycle monitoring in your IT environment, you must have visibility into your applications' current health and performance and its underlying infrastructure. Just as you need regular check-ups, you must regularly look at how your applications are performing, trends that provide insights into behavior changes, resource consumption, failures, and more. By doing this, you can control your IT environment rather than it controlling you and your organization. Effective life cycle monitoring means having your finger on the pulse of your applications and puts you in a position to act quickly when there are issues.
There are proven ways to limit problems and minimize the amount of troubleshooting needed using life cycle monitoring, but suggesting you could eliminate it would be a lie. Effective, fast, and accurate troubleshooting saves time and reduces the impact on internal users, customers, and your business.
The last part of the life cycle monitoring puzzle is capacity planning and optimization. With the right strategy and tools, you can easily leverage your insights into your environment and plan for change. You can manage trends in usage, customer growth, seasonal change, budgetary constraints, and others. In addition to managing change, you want to maximize your IT investment by optimizing all the resources in your environment. Both planning and optimization benefit from your visibility into your environment and your learnings when solving problems.
An Ounce of IT Life Cycle Monitoring Is Worth a Pound of IT Cure!
SolarWinds Solution for Monitoring Hybrid Systems
The SolarWinds® hybrid systems monitoring solution combines four tightly integrated products running on a common platform (the Orion® Platform) that leverage a set of robust shared services: Server & Application Monitor, Virtualization Manager, Log Analyzer, and Server Configuration Monitor. These core products are a foundation to providing visibility, fast and accurate troubleshooting, capacity planning, and optimization of your IT environment to support more effective life cycle monitoring. Let's dig deeper into how these products can help improve life cycle monitoring, one element at a time.
Visibility
Before you can solve problems or plan ahead, you have to take a visual inventory of your network and systems. The ability to see your environment on a single display, map dependencies, and be alerted on potential issues with insights like predictive virtual machine (VM) recommendations can open up a whole new world of possibilities and insights into your IT environment. Get comprehensive visibility into the health and performance of your physical and virtual servers, including hypervisors, whether monitoring hybrid cloud, on-premises, hyperconverged, or in the cloud.
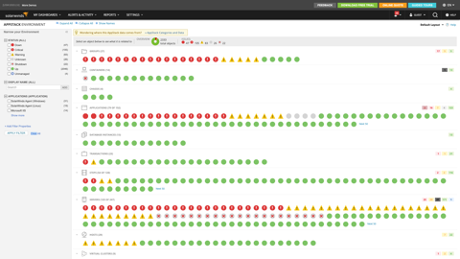
The AppStack Dashboard – An interactive map. Shows status and relationships across the IT stack
Dashboard – An interactive map. Shows status and relationships across the IT stack
SolarWinds hybrid systems monitoring solutions enable broad and targeted visibility across your application stack. With SolarWinds, you can:
- Set your monitoring environment up with over 1,200 out-of-the-box infrastructure and application monitoring templates.
- Create unique views into your environment. Visibility to a SysAdmin means one thing, but it could mean something different to a DBA, operations, or the application team. Each person or department can build views specific to what they need visibility into using one platform, one source of truth, cut multiple ways.
- Get hardware health and status of your physical IT assets.
- Leverage key metrics and logging data to better understand how applications are performing.
- Be notified the moment a server configuration changes.
- Provide your team visibility across the entire application stack.
Troubleshooting
It doesn't matter how well you manage your IT environment; stuff happens. Changes are happening more frequently, and with ever-increasing complexity, things will happen, people make errors, resources that were fine just yesterday are suddenly strapped. Time isn't your friend, and you can't afford to be wrong when identifying the root cause of a problem. SolarWinds hybrid systems monitoring solution is designed to help you troubleshoot quickly and accurately when downtime or application performance issues occur.
One example of a powerful troubleshooting function is the PerfStack feature. The PerfStack feature allows you to drag and drop system, network, log, event, and configuration metrics to visually correlate data from multiple Orion Platform products into a single customized view. You can accelerate troubleshooting by correlating multiple metrics, events, configuration changes, and more, making it easy to pinpoint the root cause impacting application performance.
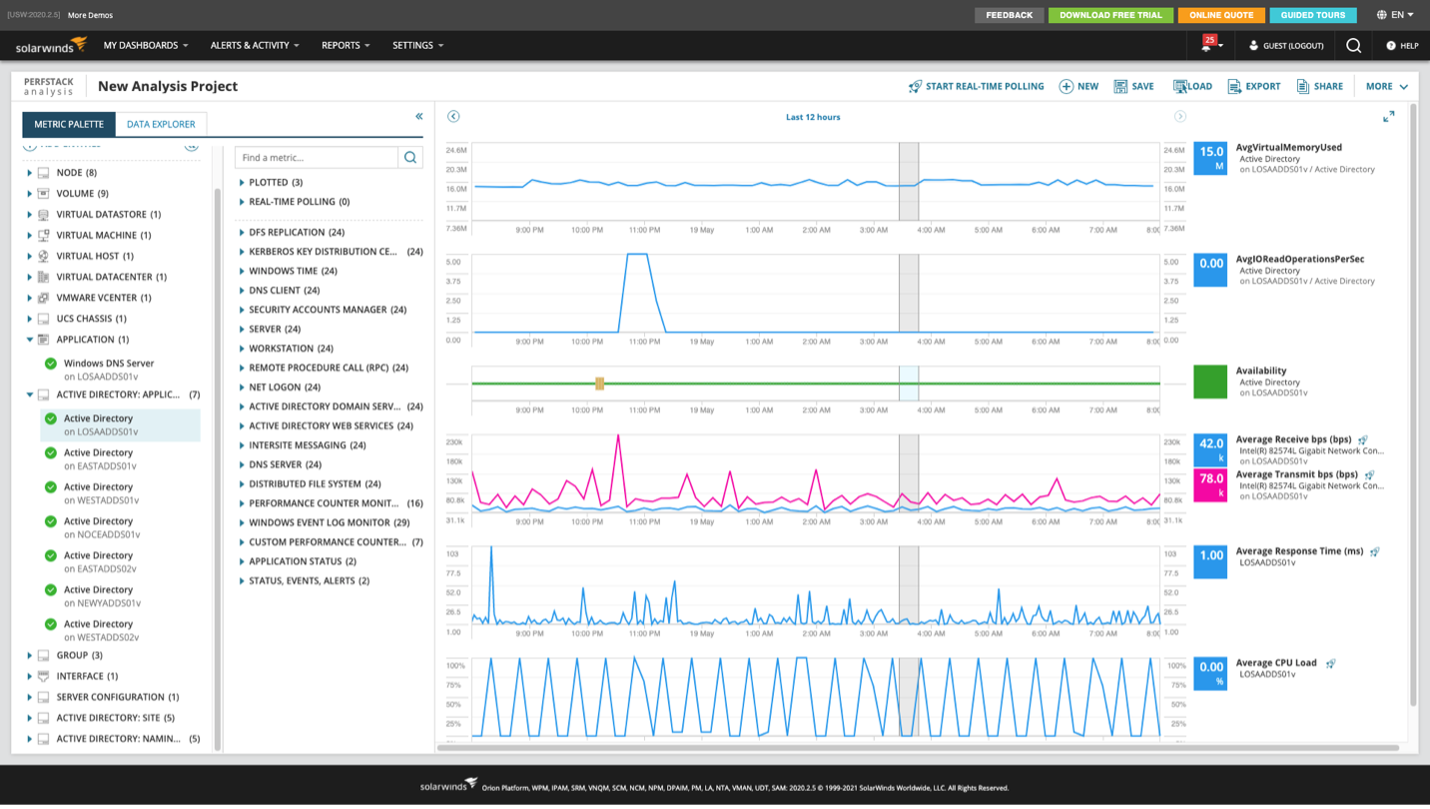
PerfStack dashboards can be used for troubleshooting projects that visually correlate data
Troubleshooting with SolarWinds hybrid monitoring solution also enables you to get:
- Visualizations of logical and physical relationships, so you can gain insights into connection ports, services, network latency, packet loss, and TCP data. With an application dependency mapping tool, you can create custom maps of groups or entities to track the response time of dependent services.
- Combined metrics with VMware event logs to help identify and manage slow-running processes, services, logs, and scheduled tasks.
- Remote server monitoring to resolve problems with built-in server management actions: the Real-Time Process Explorer identifies resource hogs and allows you to kill processes affecting server performance.
- A historical account of configuration data and infrastructure relationships to help you identify what dependencies existed at a specific time, such as VMs belonging to a host seven days ago. This data can be used to answer the "What changed?" question all IT pros regularly face when troubleshooting an availability or performance problem.
- The ability to visualize and monitor syslog, SNMP traps, or WindowsEevent logs in real-time for the near-instantaneous insights you need for effective troubleshooting.
Capacity Planning and Optimization
At its core, capacity planning and optimization involve monitoring and alerting physical or virtual server resources, such as CPU, memory, disk, and network. Forecasting when server(s) will run out of resources and planning VM capacity is essential to help optimize your current and future infrastructure investments. The problem with proper capacity planning and optimization is struggling to find the time to do it on a repeatable basis while fighting fires and keeping up with a changing hybrid environment.
SolarWinds hybrid systems monitoring provides capacity planning tools designed to simplify capacity planning and help optimize resources used to support your present and future hybrid infrastructure needs. These tools minimize the time spent gathering the necessary information and maximize the impact of a proper capacity planning program. To simplify capacity planning and optimization and reduce the time required, an IT organization should have access to built-in forecast charts and metrics to help identify when physical or virtual server resources reach warning and critical thresholds. It should enable IT professionals, to optimize server and hardware resource investments through right-size resource allocation. Lastly, there needs to be a modeling function to project future server and hardware additions and see if their environment can scale to meet workload needs.
The SolarWinds hybrid systems monitoring solution provides the capabilities needed to do both capacity planning and optimization, leveraging the functionality built into the products. From predictive and forecasting functions to recommendations and click-level implementation of those recommendations that ensure you are maximizing your IT investments.
In addition to the solution I've discussed in this article, some additional capabilities can be added, also tightly integrated on the Orion Platform and leveraging the same shared services. For example, SolarWinds Web Performance Monitor brings the user perspective into the picture with synthetic monitoring, and Storage Resource Monitor brings another level of granularity into your monitoring of specific storage systems.

VMAN - Built-in, actionable intelligence that provides recommendations to optimize your VMs
The solution enables you to optimize your IT environment and plan for change by:
- Helping you understand historical and current resource capacity
- Enabling you to optimize physical and virtual resources to right-size and maximize performance
- Providing capacity forecasting
- Including what-if resource modeling for future server and hardware additions
- Providing load balancing for resource utilization and better VM performance
- Mitigating unauthorized changes
- Validating that changes are correctly implemented
- Monitoring for changes to previously optimized servers, applications, and databases
- Providing hardware and software inventory lifecycle management impacting your investment, capacity, licenses, warranty status, and more
If you’re interested in learning more or trying our hybrid life cycle monitoring solution - Hybrid Monitoring Solution
You can also go to our interactive demo system and experience the hybrid systems monitoring solution in addition to our network offerings and other Orion Platform-based functions. Interactive Demo
