We are running Solarwinds DPA on our MS SQL Server machine running SQL Server 14.0.3456.2
We set up the " Total SQL Wait Time - Machine" alert with an execution interval of one hour. An hour later it tells me the total wait time for that hour was 2 seconds.
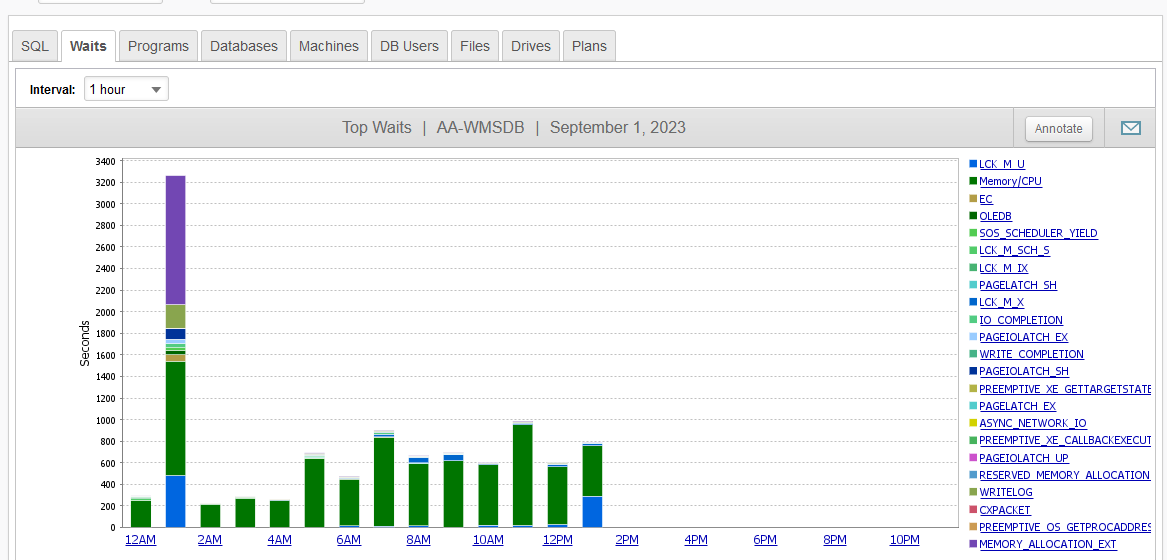
DPA shows the graph below, which I interpret to mean that over the last hour we were seeing more like 800 seconds of wait time. What is the cause of this discrepancy, and how can I make the alert more closely match the results in the DPA graph?
alert text is:
Alert: Total SQL Wait Time - Machine
Database Instance: AA-WMSDB
Execution Time: Friday - September 01, 2023 13:42:04
View Alert Status: rp-orion:8123/.../alerts
Alert Parameters:
Machine: AA-WMSDB
Thanks,
Tim
Value: 2 seconds
This message was system-generated. Do not reply to this message

