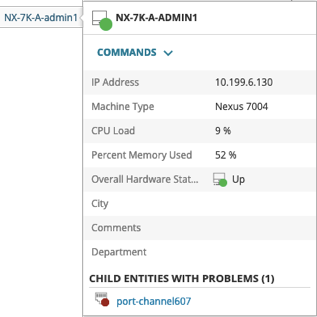
Status is arguably one of the most important aspects of any monitoring solution. It's a key component for visually notifying you that something is amiss in your environment, as well as being an important aid in the troubleshooting process. When used properly, status is also the engine that powers alerting, making it an absolutely essential ingredient for both proactive and reactive notifications aimed at ensuring your entire IT environment runs smoothly.
Orion Node Status, in particular, has for a very long time been somewhat unique when compared to other entities in Orion. Most other entities have a fairly simple, straightforward, and easy to understand the hierarchy of status based upon severity. These include things like 'Up', 'Warning', 'Critical', and 'Down', but can also include other statuses which denote an absence of a state, such as 'Unknown', Unmanaged', etc. By comparison, a node managed in Orion today can have any of twenty-two unique statuses. Some of these statuses can to the uninitiated, appear at best contradictory, and at worst, just downright confusing. This is the result of separating information about the node itself from its associated child objects like interfaces and applications into multiple colored balls. The larger colored ball representing the reachability of the node, usually via ICMP, while the much smaller colored ball in the bottom right represents the worst state of any of the node's child objects.
| Primary Node Status | Nodes With Child Status |
|---|
 | 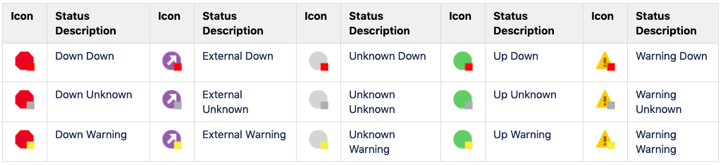 |
It would be fair to say that this is neither obvious, nor intuitive, so in this release, we've sought to radically improve how Node status is calculated and represented within Orion.
Node Thresholds
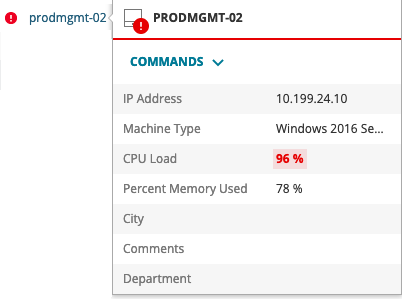
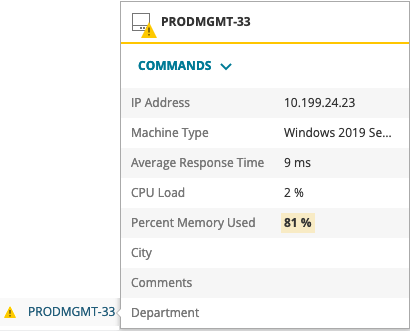
The first thing people usually notice after adding a few nodes to Orion is that node thresholds for things like CPU & Memory utilization appear to have no effect on the overall status of the node, and they'd be right. Those thresholds can be used to define your alerts, but node status itself has historically only represented the reachability of the node. That, unfortunately, complicates troubleshooting by obfuscating legitimate issues, as well as adds unnecessary confusion. For example, in the image below, I'm often asked why the state of the node itself is 'green' when CPU Load and Memory utilization is obviously critical? A very fair and legitimate question.

With the release of Orion Platform 2019.2 comes the introduction of Enhanced Node Status. With this new Enhanced Node Status, thresholds defined either globally or on an individual node itself can now impact the overall status of the node. For example, if the memory utilization on a node is at 99% and your 'Critical' threshold for that node is 'Greater than 90%', the node status will now reflect the appropriate 'Critical' status. This should allow you to spot issues quickly without having to hunt for them in mouse hovers or drilling into Node Details views.
| CPU Load | Memory Utilization |
|---|
 |  |
| Response Time | Packet Loss |
|---|
 |  |
Sustained Thresholds
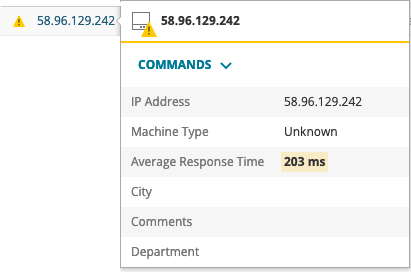
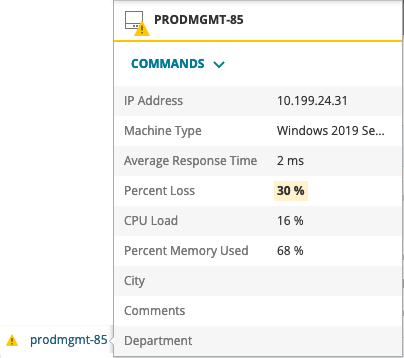
Borrowing heavily from Server & Application Monitor, Orion Platform 2019.2 now includes support for sustained node threshold conditions. Being notified of every little thing that goes bump in the night can desensitize you to your alerts, potentially causing you to miss important service impacting events. For alerts to be valuable, they should be actionable. For example, just because a CPU spikes to 100% for a single poll probably doesn't mean you need to jump out of bed in the middle of the night and VPN into the office to fix something. After all, it's not that unusual for a CPU to spike temporarily, or latency to vary from time to time over a transatlantic site-to-site VPN tunnel. What you probably want to be notified of instead, is if that CPU utilization remains higher than 80% for more than 5 consecutive polls, or if the latency across that site-to-site VPN tunnel remains greater than 300ms for 8 out of 10 polls. Those are likely more indicative of a legitimate issue occurring in the environment which requires some form of intervention to correct.

Sustained Thresholds can be applied to any node's existing CPU Load, Memory Usage, Response Time, or Percent Packet Loss thresholds. You can also mix and match 'single poll', 'X consecutive polls', and 'X out of Y polls' between warning and critical thresholds for the same metric for even greater flexibility. Sustained Thresholds can even be used in combination with Dynamic Baselines to eliminate nuisance alerts and further reduce alert fatigue, allowing you to focus only on those alerts which truly matter.
Null Thresholds
A point of contention for some users has been the requirement that all Node thresholds must contain some value. Those could be nodes that you still want to monitor, report, and trend upon those performance metrics, but not necessarily be alerted on, such as staging environment, machines running in a lab, decommissioned servers, etc. Historically there has been no way to say 'I don't care about thresholds on this node', or 'I don't care about this particular metric'. At best, you could set the warning and critical thresholds as high as possible in the hopes of getting close to eliminating alerts for metrics on those nodes you don't necessarily care about. Alternatively, some customers update and maintain their alert definitions to exclude metrics on those nodes they don't want to be alerted on. A fairly messy, but effective solution. But one which is no longer necessary.
With the introduction of Enhanced Status in Orion Platform 2019.2, now any Node threshold can be disabled simply by editing the node and unchecking the box next to the warning or critical thresholds of the metric you're not interested in. Don't want a node to ever go into a 'Critical' state as a result of high response time to keep the bossman off your back, but still want to receive a warning when things are really bad? No worries, just disable the 'Critical' threshold, leave the 'Warning' threshold enabled and adjust the value to what constitutes 'really bad' for your environment.
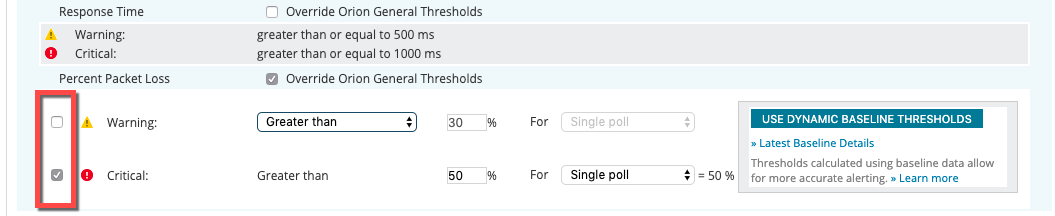
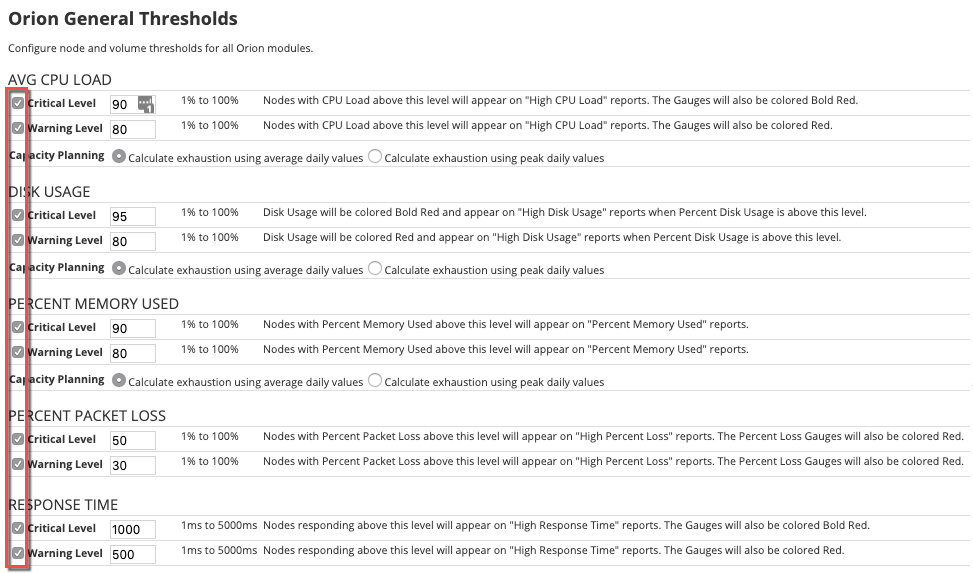
If so included, you can even disable these individual warning and critical thresholds globally from [Settings > All Settings > Orion Thresholds] for each individual node metric.
Child Objects
In this new world of Enhanced Status, no longer are there confusing multi-status icons, like 'up-down' or 'up warning'. Child objects can now influence the overall node status itself by rolling up status in a manner similar to Groups or how Server & Application Monitor rolls-up status of the individual component monitors that make up an Application. This provides a simple, consolidated status for the node and it's related child entities. Those child objects can be things such as Interfaces, Hardware Health, and Applications monitored on the node, to name only a few.
Similar to Groups, we wanted to provide users with the ability to control how node status rollup was calculated on an individual per-node basis for ultimate flexibility. When editing the properties of a single node or multiple nodes, you will now find a new option for 'Status roll-up mode' where you can select from 'Best', 'Mixed', or 'Worst'.
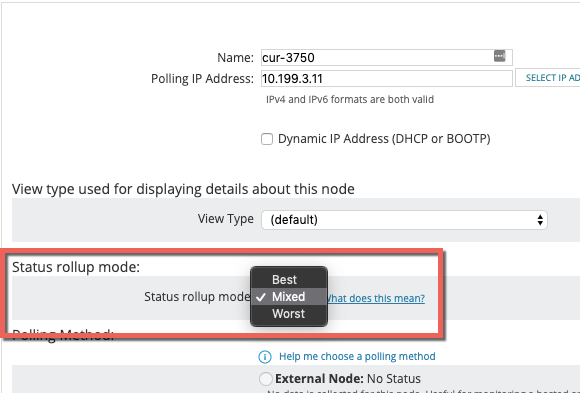
By altering how node status is calculated you control how child objects influence the overall status of the node.
Best status as one might guess, always reflects the best status across all entities contributing to the calculation. Setting the Node to 'Best' status is essentially the equivalent of how status was calculated in previous releases, sans the tiny child status indicator in the bottom right corner of the status icon.
Worst status, you guessed it, represents the status of the object in the worst state. This can be especially useful for servers, where application status may be the single most important thing to represent for that node. E.G. I'm monitoring my Domain Controller with Server & Application Monitor's new AppInsight for Active Directory. If Active Directory is 'Critical', then I want the node status for that Domain Controller to reflect a 'Critical' state.
Mixed-status is essentially a blend of best and worst and is the default node status calculation. The following table provides several examples of how Mixed status is calculated.
| Polled Status | Child 1 Status | Child 2 Status | Final Node Status |
|---|
| DOWN | ANY | ANY | DOWN |
| UP | UP | UP | UP |
| UP or WARNING | UP | WARNING | WARNING |
| UP or WARNING | UP | CRITICAL | CRITICAL |
| UP or WARNING | UP | DOWN | WARNING |
| UP or WARNING | UP | UNREACHABLE | WARNING |
| UP | UP | UNKNOWN | UP |
| WARNING | UP | UNKNOWN | WARNING |
| UP | UP | SHUTDOWN | UP |
| UP or WARNING | DOWN | WARNING | WARNING |
| UP or WARNING | DOWN | CRITICAL | CRITICAL |
| UP or WARNING | DOWN | UNKNOWN | WARNING |
| UP or WARNING | DOWN | DOWN | WARNING |
| UP | UNKNOWN | UNKNOWN | UP |
| WARNING | UNKNOWN | UNKNOWN | WARNING |
| UNMANAGED | ANY | ANY | UNMANAGED |
| UNREACHABLE | ANY | ANY | UNREACHABLE |
| EXTERNAL | ANY | ANY | Group Status |
In case you overlooked it in the table above, yes, External Nodes can now reflect an appropriate status based upon applications monitored on those nodes!
Child Object Contributors
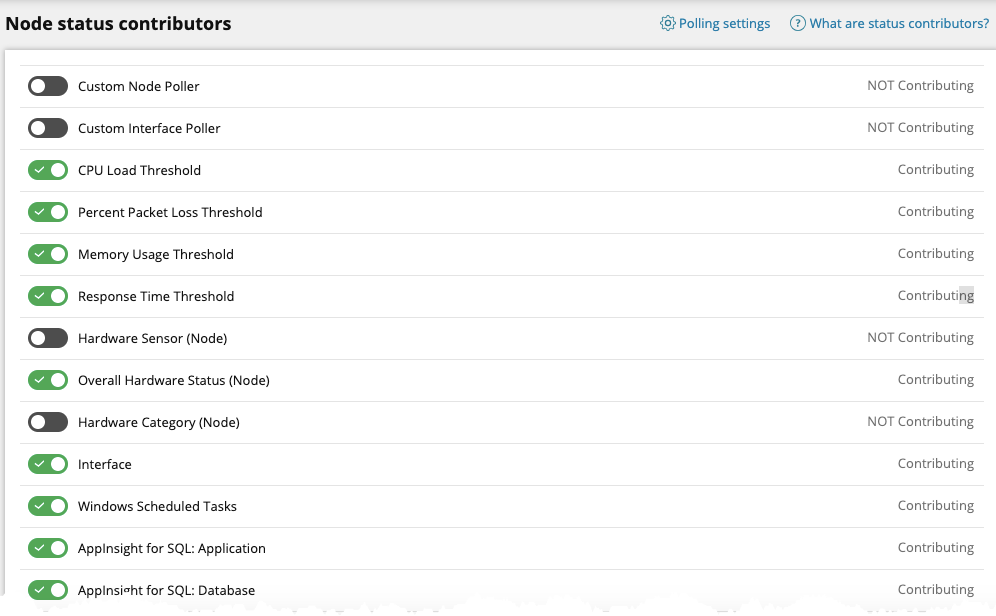
Located under [Settings > All Settings > Node Child Status Participation] you will find you now have even more fine-grained granular control of up to 27 individual child entity types which can contribute to the overall status of your nodes. Don't want Interfaces contributing to the status of your nodes? No problem! Simply click the slider to the 'off' position and Interfaces will no longer influence your nodes status. It's just that easy.
Show me the Money!
You might be asking yourself, all these knobs, dials, and switches are great, but how exactly are these going to make your life better or simpler? A fair question, and one which no doubt has countless correct answers, but I'll try and point out a few of the most obvious examples.
Maps
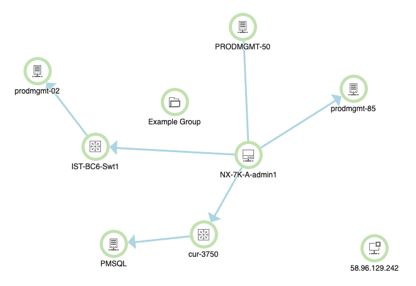
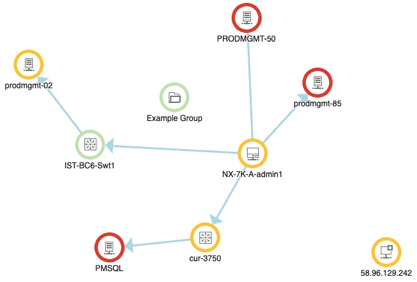
One of the first places you're likely to notice Enhanced Status is in Orion Maps. The example below shows the exact same environment. The first image shows what this environment looked like in the previous release using Classic Status. Notice the absence of any obvious visual cues denoting issues in the environment. The next image to the right is of the very same environment, taken at the exact same time as the image on the left. The only notable difference is that this image was taken from a system running Orion Platform 2019.2 with Enhance Node Status.
In both examples, there are the exact same issues going on in the environment but these issues were obfuscated in previous releases, making the troubleshooting process less intuitive and unnecessarily time-consuming. With Enhance Status it's now abundantly clear where the issues lie, and with the topology and relationship information from Orion Maps, it's now easier to assess the potential impact those issues are having on the rest of the environment.
| Classic Status | Enhanced Status |
|---|
 |  |
Groups
Groups in Orion are incredibly powerful, but historically in order for them to accurately reflect an appropriate status or calculate availability accurately, you were required to add all relevant objects to that group. This means you not only needed to add the nodes which make up the group, but also all child objects associated with those nodes, such as interfaces, applications, etc. Even in the smallest of environments, this was an otherwise impossible feat to manage manually, and given the nature of all the various entity types which could be associated with those nodes even Dynamic Groups were of little assistance in this regard. Enhanced Status not only radically simplifies group management, but it also empowers users to more easily utilize Dynamic Groups to make group management a completely hands-off experience,
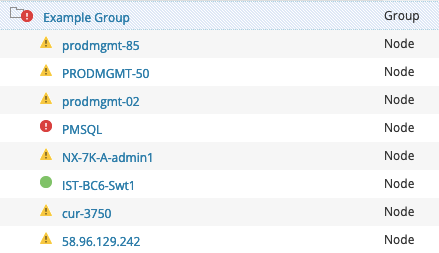
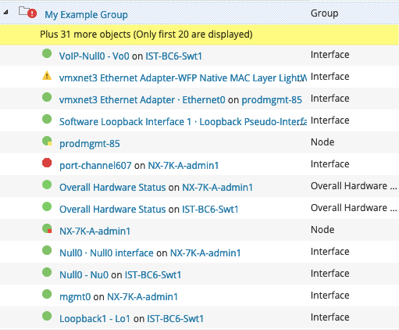
The following demonstrates how Enhanced Node Status simplifies overall Group Management in Orion, reducing the total number of objects you need to manage inside those groups. The screenshot on the left shows a total of eight nodes using Enhanced Status in a group, causing the group to reflect a Critical status. The image to the right shows all the objects that are required to reflect the same status using Classic Status. As you can see, you would need to not only add the same eight nodes, but also their 43 associated child objects, for a total of 51 objects in the group. Yikes!
| Enhanced Status (8 Objects) | Classic Status (51 Objects) |
|---|
 |  |
By comparison, the following demonstrates what that group would look like with just the eight nodes alone included in the group using both Classic Status and Enhanced Status. Using Classic status the group reflects a status of 'Up', denoting no issues at all in the group. With Enhanced Status, it's abundantly clear that there are in fact issues, which nodes have issues, and their respective severity. This aids in significantly reducing time to resolution and aids in root cause analysis.
| Enhanced Status | Classic Status |
|---|
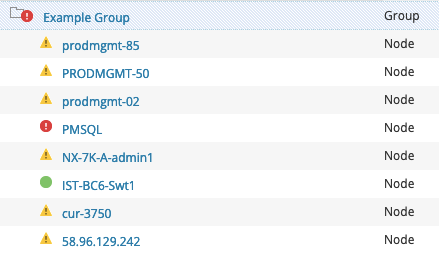 | 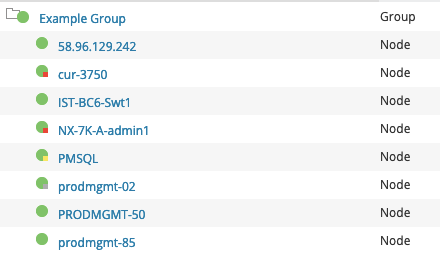 |
Alerts
Possibly the greatest benefit of Enhanced Status is that far fewer alert definitions are required to be notified of the exact same events. Because node thresholds and child objects now influence the status of the node, you no longer need alert definitions for individual node metrics like 'Response Time', or related child entities like 'Interfaces'. In fact, of the alert definitions included out-of-the-box with Orion, Enhanced Status eliminates the need for at least five, taking you from seven down to a scant two. That's a 71% reduction in the number of alert definitions that need to be managed and maintained!
| Out-of-the-box Alerts Using Classic Status - x7 |
|---|
 |
| Out-of-the-box Alerts Using Enhanced Status - x2 |
|---|
 |
Alert Macros
I'm sure at this point many of you are probably shouting at your screen "But wait! Don't I still need all those alert definitions if I want to know why the node is in whatever given state that it's in when the alert is sent? I mean, getting an alert notification telling me the node is 'Critical' is cool and all, but I sorta need to know why."
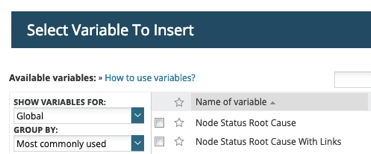
We would be totally remiss if in improving Node status we didn't also improve the level of detail we included in alerts for nodes. With the introduction of Enhanced Status comes two new alert macros which can be used in your alert actions, such as email notifications, which lists all items contributing to the status of that node. Those two alert macros are listed below. The first is intended to be used with simple text-only notification mechanisms, such as SMS, Syslog or SNMP Traps. The second macro outputs in HTML format with hyperlinks to each child objects respective details page. This macro is ideally suited for email or any other alerting mechanism which can properly interpret HTML.
- ${N=SwisEntity;M=NodeStatusRootCause}
- ${N=SwisEntity;M=NodeStatusRootCauseWithLinks}
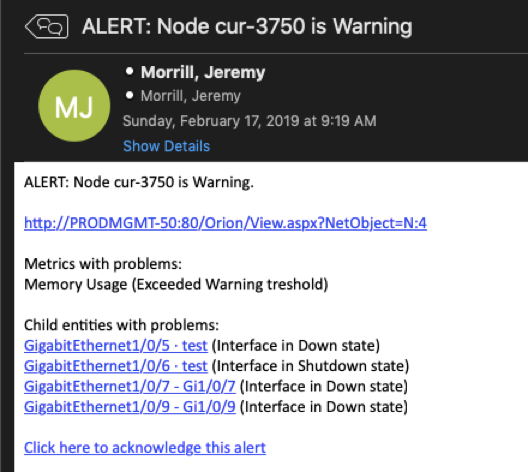
The resulting output of the macro provided in the notification includes all relevant information pertaining to the node. This includes any node thresholds which have been crossed, as well as a list of all child objects in a degraded state associated with the node. All consolidated down into a simple, easily digestible, alert notification that pinpoints exactly where to begin troubleshooting.
Enabling Enhanced Status
If you're installing any Orion product module for the first time running Orion Platform 2019.2 or later, Enhanced Status is already enabled for you out-of-the-box by default. No additional steps are required. If you're upgrading from a previous release, however, you will need to enable Enhanced Status manually to appreciate the benefits it provides. Because status is the primary trigger condition for alerts, we did not want customers who are upgrading to be surprisingly inundated with alert storms because of how they had configured the trigger conditions of their alert definitions. We decided instead to let customers decide for themselves when/if to switch over to Enhanced Status. The good news is that this is just a simple radio button located under [Settings > All Settings > Polling Settings]

Conversely, if you decided to rebuild your Orion server and have a preference for 'Classic' status, you can use this same setting to disable Enhanced' Status mode on new Orion installations and revert back to 'Classic' status.
Cautionary Advice
If you plan to enable 'Enhanced' status in an existing environment after upgrading to Orion Platform 2019.2 or later, it is recommended that before doing so that you disable alert actions in the Alert Manager. This should allow you to identify alerts with trigger conditions in their alert definition which may need tweaking without inadvertently causing a flood of alert notifications or other alert actions from firing. Your coworkers will thank you later for doing so.
Feedback
Enhanced status represents a fairly significant, but vitally important change for Orion. We sincerely hope you enjoy the additional level of customization and reduced management overhead it provides. As with any new feature, we'd love to get your feedback on these improvements. Will you be switching to Enhanced Status with your next upgrade? If not, why? Be sure to let us know in the comments below!