(Original blog post: Exported Alert: Change The SolarWinds Status Icon When A Device Has A Problem | Prosperon Networks )
Hi Thwackers
A common complaint that I receive when I’m onsite delivering consultancy or training on SolarWinds is that alerts can be disconnected from what you see for the device status on the web interface. I understand that this is quite annoying when you check a device and you see its status is green when the same device has a critical alert.
SolarWinds was aware of that, hence, they added a feature into the Orion alerting engine that allows us to customise the status of the device using alert actions. On any alert, you can add the trigger action to change the status to something customised. Just to give you a little bit more background into how this works, by default, the up/down status of a device depends on the polling method (normally ICMP ping). If the device replies to the ping from the SolarWinds server, it will display the green icon (up), if not, it will display the red icon (down).
When this new feature was released, SolarWinds added two more possible statuses: critical and warning. To be honest, the warning status has been available for a while. This status is used when a device misses the first ping and starts the warning level. During a validation period, the device stays in warning status until it starts replying to ping or after two minutes when the status changes to down. Critical status though was completely brand new.
Even though I loved this idea, I found it was not so easy to use. To explain myself better, let me use this example:
- Node ‘A’ triggers an alert that changes the status to ‘critical’.
- Sometime later, Node A triggers another alert that changes the status to warning.
Now we have Node A with two active alerts; one critical, and one warning, but the status of node A is warning because the last alert overwrote the status from critical to warning.And this could be even worse, imagine that when the second alert (the warning) is cleared, and this clears the warning status, reverting its status to the normal polled status, i.e. up status. Therefore, we would have Node A with a critical alert showing as status is up.
The Solution
The solution I came up with is to create a brand-new alert that will be triggered if a device has one or more active alerts, changing the status to whatever custom status we want. This alert will be reset when there are no active alerts, assigning the polled status to the node. This way we make sure that the status is not overwritten when it shouldn’t be. Basing this on alerts that are already active on a device also means we can be more intelligent about the appropriate status applied to the device.The way I’ve configured these alerts is:
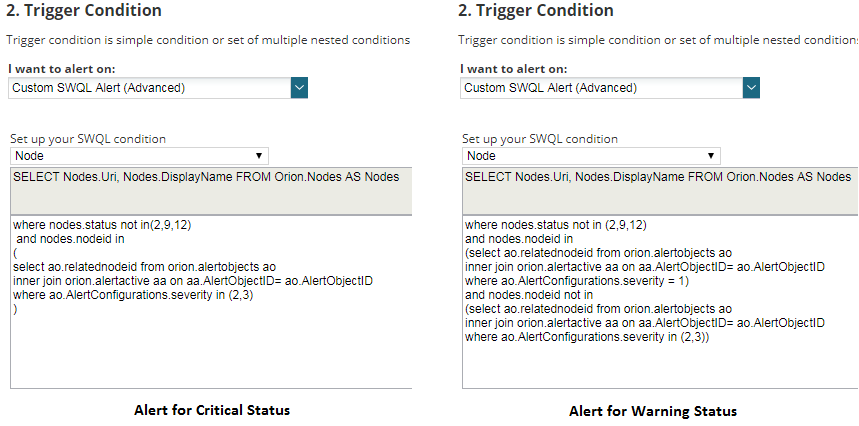
- Alert 1: Change status to critical if a node that is not down, unmanaged or unreachable has at least one critical or serious alert.
- Alert 2: Change status to warning if a node that is not down, unmanaged or unreachable has at least one warning alert but no critical or serious alert.
If you agree with me, good news! I’ve created these alerts and made them available below. To be honest these alerts are not too difficult to create:
- Trigger conditions: I’ve used SWQL for nodes, which is a little more advanced but brings great power and control.
- Reset conditions: when trigger conditions are no longer true.
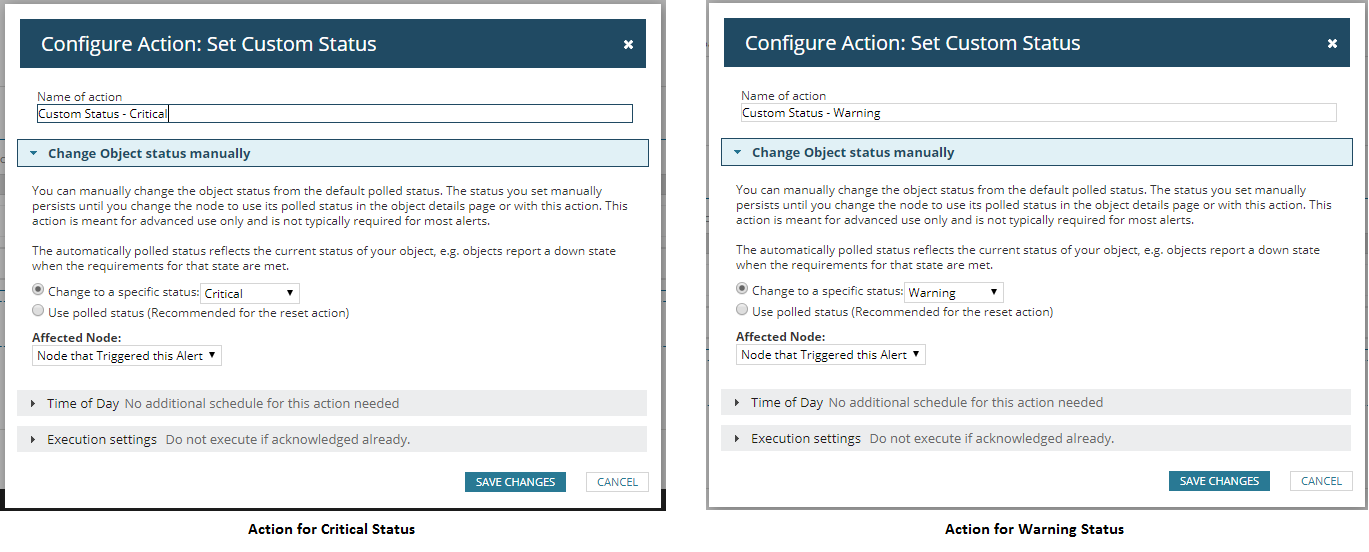
- Trigger action: changes the status to the chosen status (warning or critical).
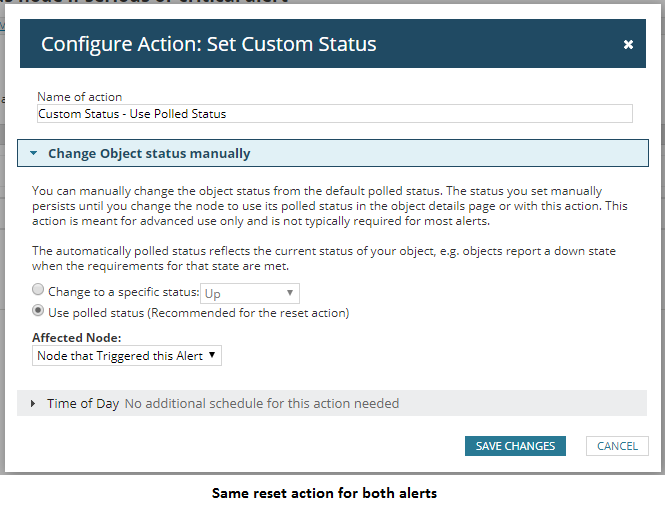
- Reset action: changes the status to the polled status (probably up).
NOTE: You might have a different idea on when to assign a custom status, so feel free to modify the scripts, but hopefully this has got your creative juices flowing.
I hope these alerts help you guys get a clearer understanding of which devices are having problems and which ones are ok.
Raul Gonzalez
Prosperon - UK SolarWinds Partners
Installation | Consultancy | Training | Licenses
