So, I am aware of this thread: https://thwack.solarwinds.com/product-forums/network-configuration-manager-ncm/f/forum/55296/backup-failure-alerts And I am also aware the job logs can be emailed, but that is a very crude email or don't email approach.
I also like the idea of the mop up action that @RichardLetts showed, and I can see that working in some cases for us but not for all. We have >100 weekly backup schedules which attempt to backup >6k devices. We don't want folks to manually trawl through log files as we already get blindsided enough by emails and so need an automated method to do this.
Simply stated:
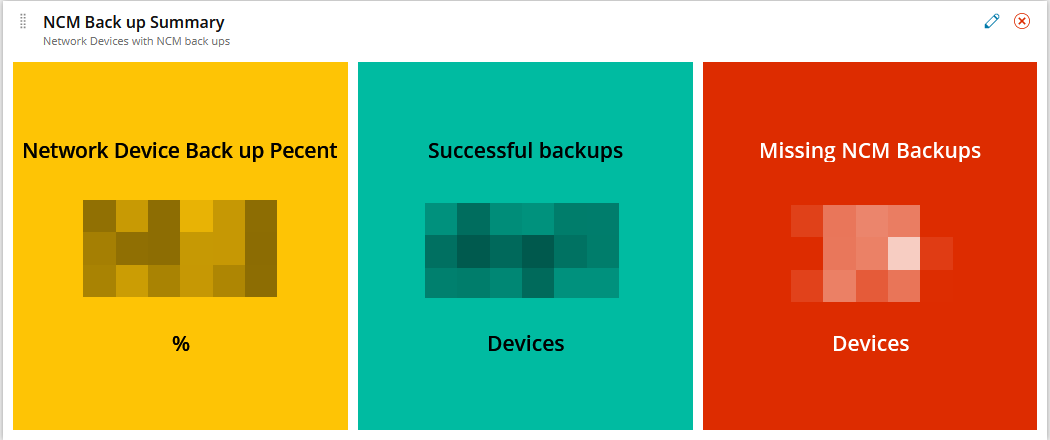
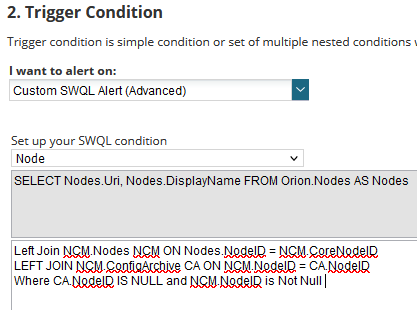
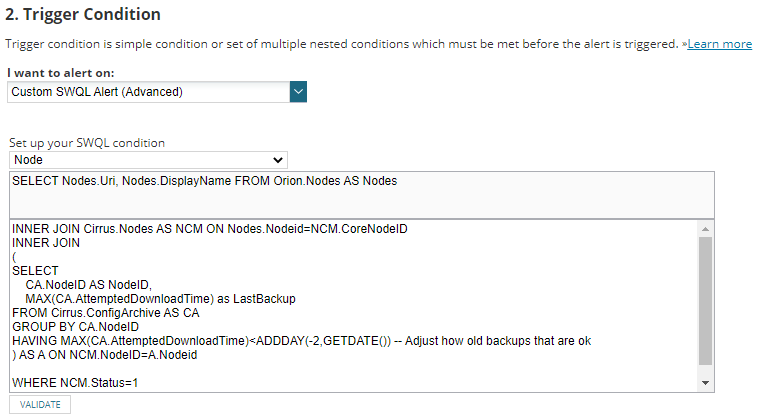
We need to alert on any specific node that fails to backup so that it can be raised as an incident.
- personally speaking I know this is likely to raise more manual work to go and trigger a fresh backup or investigate why it is failing, but in this glorious new world of automation, this is what management want. And, let's face it, there is only so much sense you can talk to management before they start demanding stuff