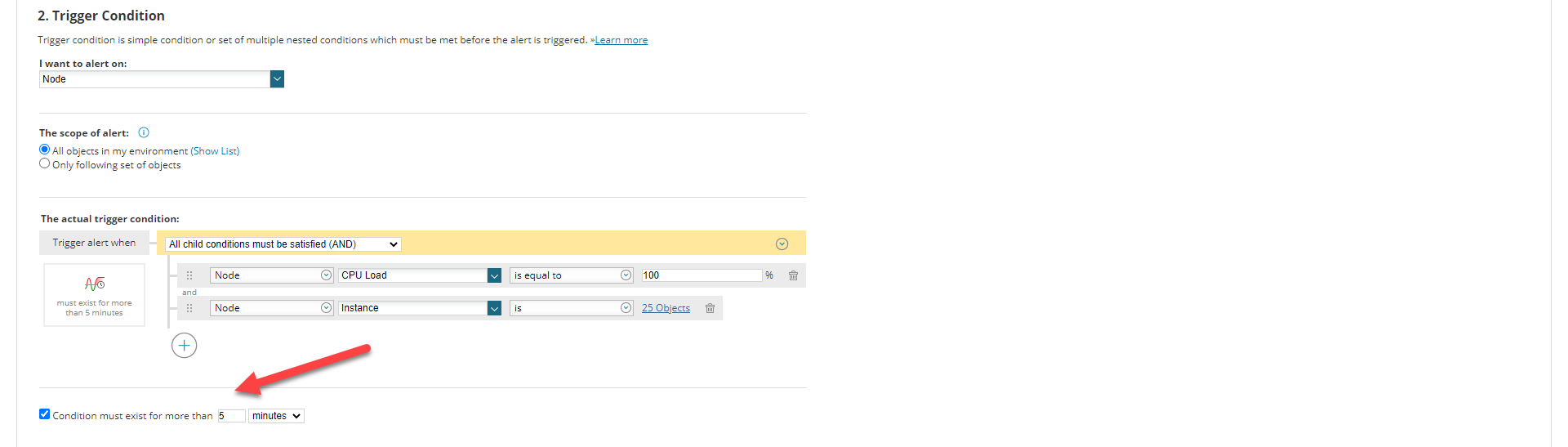
Scenario:
We have a "High CPU Alert" set for particular if the Production Node reaches High CPU for 5 minutes it triggers an email, text, etc
- Evaluation Frequency of the alert is for 1 minute
- The condition "CPU Load is equal to 100%" must exist for more than 5 minutes
Observation:
We are seeing these alerts with a lag in time between our Cloud Infrastructure and Solarwinds SAM where it's reporting 100% CPU but on the VM it's fine. We've also seen the opposite where we didn't get alerted before there was an issue but we happened to be looking at the Node in SAM and noticed the issue then got the Alert.
How can we "fine tune" this process between polling and actual results? I know there's likely always going to be some inherent lag but we should be getting the Alerts before our customers see any downtime and address the issue which is usually solved by an IIS Reset due to Worker Processes hogging the CPU.