So a year has passed since I took over this Orion environment in Google Cloud Platform and I thought I would gather my observations and lessons I struggled through and see what war stories the rest of the community might have on the topic.
So the there are two relevant points I think are critical to get out of the way. First, yes you can absolutely run Orion with good performance on any decent cloud provider. Secondly, it is not a cost saving exercise to make that happen. The migration has enabled our company to make things happen MUCH faster than they did in the old days because they basically said "Here is your project, you own everything in it and it comes directly out of your budget, good luck." I don't want to get bogged down into the weeds of the cloud/anti-cloud conversation. So I just wanted to get that cleared ahead of time.
So let's work under the assumption that word has come down from above that this is something you are doing, now the burden is on you as the SME to make it work the best you can while trying not to empty the wallet in doing so. One thing I'll mention is if you have the option to do a hybrid and keep anything on prem, I would recommend you keep your SQL server there. It is, as always, the biggest user of resources and so it will cost the most to host. My SQL server costs us double every month what we spend on any other server and it used to be 4x more expensive before I optimized it. It cost so much that it basically put a target on my back for having the most expensive hosted server in our company. Fortunately, since then there have been other big machines moved to the cloud, and I was able to cut my costs down significantly so nobody even blinks at my server anymore.
To set the context, my environment at the time of the first phases of this about 3 years ago was a Primary Server with NPM, NTA, VMAN, SRM, SAM and DPA. 10 additional polling engines, and 4 additional web servers, ~13,000 Nodes and 70,000 elements. We don't run the HA module but our SQL backend is in an availability group. About half our environment is on prem network hardware scattered around the world at 300 sites, then 1/4 are legacy servers that haven't moved out of our last remaining data center, and 1/4 are other servers in GCP and AWS.
First off you will need to get pretty familiar with the Orion requirements documentation, https://documentation.solarwinds.com/en/Success_Center/orionplatform/content/core-orion-requirements-sw1916.htm
SW has already written up their recommendations for instance sizes and officially supports running your DB hosted in AWS RDS and Azure SQL DB or on a self managed instance where you install your own SQL. In our case, GCP still isn't officially listed, and back at the time when this journey began GCP SQL wasn't ready for our use case so we built our own SQL instance. We also host a few other application databases that my team uses in this same instance so trying to chase down compatibility across all the vendors would still have forced us to go this route regardless. Maybe in a few more years I'll cut over to a fully cloud managed DB when we cut loose a few of those last stragglers.
Additionally you need to start learning some of the arcane details of your specific cloud. There are a ton of little details in these docs that are going to explain all kinds of quirks and bottlenecks you run into that you would never have realized exist so the sooner you read these things cover to cover the better off you will be.
For me in GCP, https://cloud.google.com/compute/docs/concepts
AWS, https://docs.aws.amazon.com/AWSEC2/latest/WindowsGuide/concepts.html
Azure, https://docs.microsoft.com/en-us/azure/virtual-machines/
So my team did what is probably a common thing, they just mirrored their on prem VM resources to a roughly matching instance type. On prem we had a VM with 12 cpu and 30 GB of ram and that was working well enough so thats what we wanted in the cloud. This will usually do the job but when it comes to cloud strategy the name is of the game is optimization, and there are subtle differences between the types of machines each cloud vendor offers you may want to be aware of. It will really benefit you to familiarize yourself with their offerings because each category represents various trade offs between costs and performance in ways that might end up catching you off guard if you don't read up. On the plus side, it's usually not very hard to switch an instance from one type to another as long as you can schedule a reboot. In GCP, for example, there are shared core machines as the most budget friendly option, N1 are on legacy hardware, N2 is a bit more expensive but runs on Intel Skylake CPU's, N2D runs on AMD Rome CPU's, and E2 which seems to have roughly the same performance as N1 did, but is just a bit cheaper. I actually use all the machine types for different use cases as part of my cost optimization strategy. Best performance where it makes the most difference, my primary server and SQL, and I use various cheaper types where I can get way with it, such as APE's and Netpath probes.
One thing that I learned painfully was if you do a lift and shift and bring all your old problems with you then in the cloud your will be paying for any sloppiness and it adds up in a way that we never really worried about in the old data center. For a time I was looking at increasing my CPU count on the APE's because occasionally I would run into high utilization that ran longer than I was comfortable with. One day I happened to be shuffling things around and noticed the CPU consumption moved when I moved a specific batch of servers to another APE. That prompted me to look closer and get into the logs and I found that there were certain polling errors that were really common in those logs, but none of them showed up as anything in the GUI so they were flying under the radar. I chased the errors down, tweaked some of my node polling options and some advanced Orion settings from a KB article and then the CPU consumption problem went away. That was encouraging, so I then spent a good chunk of time chasing down the worst gremlins across all the servers and in the end I was able to bring down the rate of polling errors to something like 30% of the initial rate. I also had less disk log writes which actually relieved some throttling I had been seeing with the disks. Once I got things running really smoothly I had so much extra CPU and memory capacity on the APE's I actually decided to stack my APE licenses and decom some servers instead. I went from having 10 separate VM's with 1 APE license each to just 4 instances. A single license poller in our DMZ network and the 3 remaining pollers with 3 licenses on each. I never ended up having to add more CPU, so now I've got 3 APE's with 12 CPU, 30 GB RAM polling >20,000 elements each and everything hums along nicely. It turns out that you can reduce a lot of resource consumption by actually fixing things instead of throwing more hardware at the problem ¯\_(ツ)_/¯ Fixing my polling errors and eventually shutting down those 6 servers took a nice chunk out of my hosting bill.
So the next big thing to talk about is the SQL server. I mentioned before that this guy is going to be the most costly, so anything you can do to optimize here shows the best return on the time invested. We have DPA, if you don't have it I strongly recommend running a trial just to help you with this tuning effort because it really is incredibly helpful when benchmarking changes to how you have your database set up and gives you actual numbers to quantify improvements. So I spent a chunk of time reviewing all the index tuning recommendations it was giving me, and trying to max out the efficiency of all the custom SWQL and SQL widgets I have all over my views. Through lots of time reading and tweaking settings in SQL server I was able to get our typical waits down by about 25% which improved overall snappiness in the tool, but then I decided to see what I could do about reducing my memory footprint. I'm not a wizard at this part so I went with a simple strategy here. I just kept cutting the Max Memory setting in SQL server and watching for changes to my Page Life Expectancy and overall waits. I would cut it back, wait a couple days, see how things ended up, then cut again. Across a few application databases our SQL instance hold about 600 GB of data, but Orion is the bulk of that. When I started our PLE was really high, it could go weeks before it would plateau out. That was telling me we had more than enough RAM to hold everything in memory pretty much forever. That sounds nice but in this case we were paying a fortune for that luxury so I kept chopping the memory down until I my PLE was reliably in the 20,000-30,000 seconds range. That's about 5-8 hours. That tells me I have enough ram to generally do most normal activities, but certain heavy duty reports and the nightly maintenance jobs will end up having to pull from disk. Generally speaking if I'm running a report that heavy I already know it's not going to happen instantly and can afford to wait. My overall wait averages really didn't change much, so that told me the user experience was still nearly as good as it was when we a boat load of RAM, but I was spending $1500 a month less on extended memory charges and I had plenty of charts to validate my impacts. My boss's boss really appreciated all that. For my system that sweet spot ended up being 16 CPU and 200 GB RAM in case you want a point of reference.
Last infra related thing I wanted to point out is there are potentially new metrics from your cloud provider that you may not be used to thinking about coming from a traditional environment. For me one of the ones that I didn't learn about for a while was that GCP has disk performance throttles that they apply any time you exceed your allowed IOPS or disk throughput. The table for figuring out your max disk is a bit complicated because it's based on the type of disk you have, multiplied by the GB of your disk, up to a cap determined by your CPU count. Keeping track of that can be a pain but the easy indicator is just to watch and see when they throttle you. If you aren't getting throttled then you know you are golden, if you get it a lot then you have something to consider.
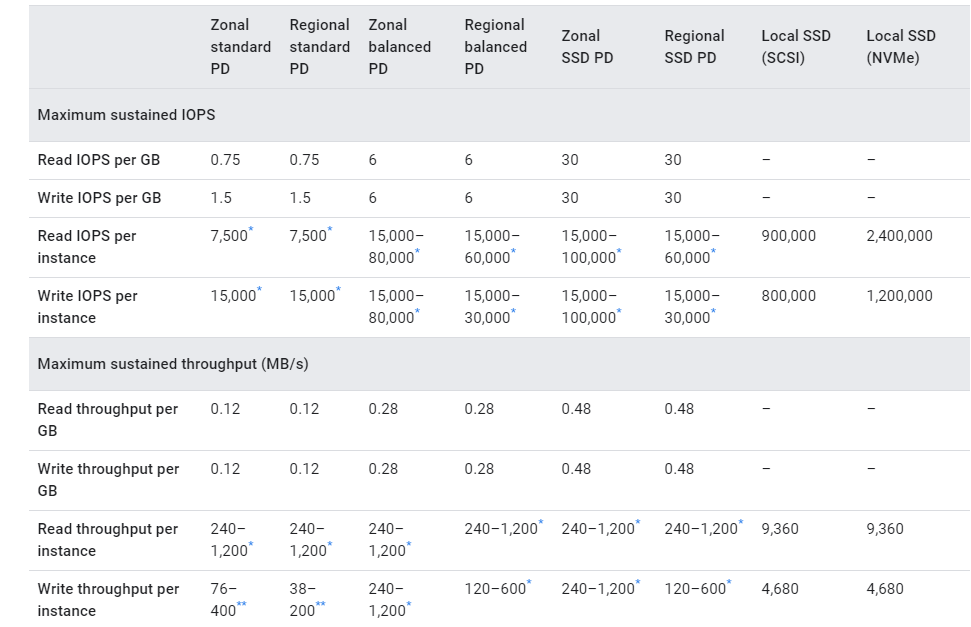
So I had already seen before that the drive of my pollers that I write logs to would get throttled by the volume of errors we were writing. It's not a huge disk and it didn't seem important so we we weren't going to make it an SSD. Fixing the polling errors actually cleared that one up. So the big outstanding issue I was seeing was on my SQL volumes. These were already big drives with SSD so we had actually already hit the peak of what GCP offers for disks short of moving to their more spendy specialty products like a dedicated local SSD. I kept an eye on the behavior and realized I was rarely being throttled on throughput, it was IOPS in almost all cases so that got me digging a bit and I realized the SQL instance still had the Windows default block size of 4k. The recommendation for SQL is normally 64k, but I found some articles indicating that the underlying GCP infra does better around 32k so I went ahead and spun up new disks in GCP, formatted them correctly, migrated my database files across and saw measurable improvements pretty quickly. Now the only time GCP throttles my disk is during DB maintenance, but the maintenance runs faster so and I can live with that.
You are likely going to end up spending some time getting familiar with your cloud's cost calculator. This is the one for GCP, https://cloud.google.com/products/calculator and I have spent many afternoons punching scenarios into it trying to figure out the right balance between costs and performance for your environment. Between all these changes I was able to bring the cloud hosting costs for my team down by $50k per year and my higher ups think I'm a hero now since there is nothing they love more than getting to go to exec meetings with cost savings.


