I posted this on the NPM section, but it was suggested I post here as well as someone might have an idea in SAM...
So I had an idea of how I can save time. I will explain the situation.
- Because of certain application within our estate, there are certain processes (java) that will sometimes use a whole lot of everything. Ram, CPU and drive space.
- I know that I could say 'if process = java >90% then do x action' this is fine (I know it's terrible logic, but bare with me here. I thought about this at 3am and am working on notes I wrote in the dark and the random thought process I am having.) I can report on a specific process, but what if it's not Java and it's for example the print spooler? I'd need another alert for this.
I want solarwinds to inform me that something is in a hung state (ergo over and hour) but then I need to determine if it's an actual issue and not a job being run during the night. I know for a fact that this seems that implementation is going to be difficult.
Once the alert has been triggered I want the server and process that's in a hung state (this is the easy bit) sent to the support mailbox and the customer. Here come's the hard bits:
With this information I would love to be able to include a screenshot of the process' that are running in the background (Maybe from a macro, or maybe solarwinds can take a report of the processes that are running at the time.) so that the customer can resolve this issus application side
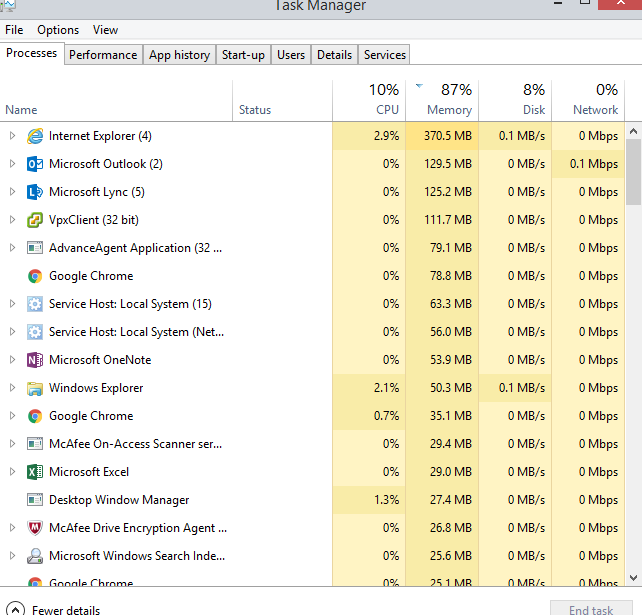
Some like and then maybe a piece explaining why this email has been sent with the server name, ect. On top of this, I would love it to happen to both CPU and memory. I don't know if it seems like a better idea than saying 'this node is running at 99% of it's memory' and of a similar nature.
My final and what I conceive a much harder thing to implement. Usually, when a drive gets full, we would log on to the server, run tree size, look at the drive, try to make space or increase the drive.
What I want to do is, have it where by treesize opens up, takes a screen dump/report of the drive and then it get's sent to the support desk and any relative parties. I know I could and would NEVER trust a system to remove files/drives themselves. But if there's a way that I can reduce the amount of time I need to log on to a sever and then investigate as little as possible, then it seems like a win win situation.
Implementation.
I made an alert that states if a process get's over 95% for 45 minutes then report the alert. I would consider this a hung state. The only thing I need to determine is if (A) the process is being run by a user generated action, or, if is because it's in a hung state.
If I truly think about this, I might be asking too much. But the idea, if implemented correctly would save me so much time when I am emergency contact.
