So had a fun little scenario occur the other day and curious how other's have addressed it. We had a node that a service went crazy and pegged the system at 100% memory utilization. The system was still responding to ping, but for everything else it was down. The node status was still up due to the ping status and never went to an unknown state. The resource monitors maintained the previous values and I did not see a change to unknown for them. I'm going to get some service monitors in place to keep an eye on it that way, and we do have alerts configured for unknown status on applications (toggleable based on some application custom properties). I could base node status off of WMI (Windows) and SNMP (Linux), but I still prefer ping in that regard.
This scenario got me thinking of ways to build in a safety net style alert. I want to try and avoid alert fatigue and not send multiple alerts for the same issue. So I was thinking of tapping into the data provided by VIM. Anyone else do something similar or have a different approach for these kind of scenarios? The object selected below is set to Virtual Machine. I am using a scope to target items based on custom properties.
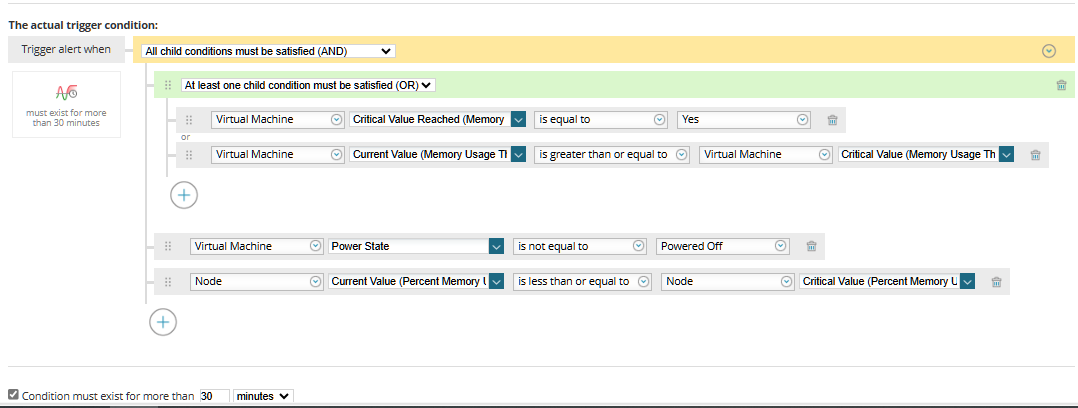
We had an issue in the past where critical values were getting reached but the critical value reached flag did not trip, hence the or block. We also like to not alert on resource utilization if a system is powered off/down.


